Logging memory and cpu usage in Ubuntu
Posted by Paul Klinkenberg in on April 16, 2014
I recently installed a cluster of Ubuntu VMs for a client's web application. Now it was time for logging and monitoring, but that turned out to be not so simple at all. I couldn't find a solid Linux script which would log CPU and memory usage, so decided to write it myself.
The script extracts data from the files /proc/meminfo and /proc/loadavg, and saves them in sysinfo.log as a tab-delimited text file. The columns are:
Date MemTotal MemFree MemCached CPU-usage (=last minute avg.)
MemTotal will always remain the same, but is usefull for calculating relative available memory. MemFree + MemCached == available memory; don't be misled by the column name "MemFree".
#!/bin/bash
FILE=/home/paulk/sysinfo.log
MEMDATA=`sudo cat /proc/meminfo | egrep "^(MemTotal|MemFree|Cached)" | sed 's/[^0-9]\+//g' | tr '\n' '\t'`
CPUDATA=`sudo cat /proc/loadavg | sed 's/ .\+//'`
if [ ! -f $FILE ]
then
echo "Date MemTotal MemFree MemCached CPU-usage" > $FILE
fi
echo "$(date) $MEMDATA $CPUDATA" >> $FILE
Steps to install/use:
-
Save this script as 'logsysinfo.sh' (for example in your home directory)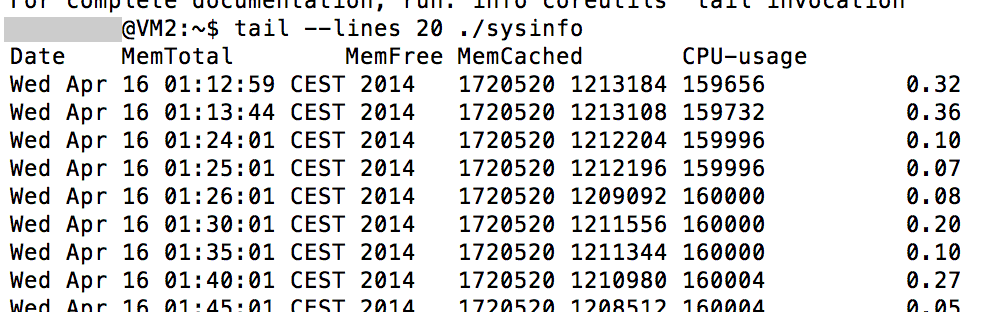
- $ nano ./logsysinfo.sh
- paste the script, then do CTRL + X
- chmod the file to 755
- $ chmod 755 ./logsysinfo.sh
- test-run:
- $ sudo ./logsysinfo.sh
- tail ./sysinfo.log
- If the output of the last command was 2 lines (1st=header, 2nd=numbers), then all is good.
- Make sure the log is updated every 5 minutes:
- $ sudo crontab -e
- add the following line in the text editor which just opened, then close the editor:
- */5 * * * * /home/paulk/logsysinfo.sh
- Wait for max 5 minutes, then do $ tail ./sysinfo.log again
- If there is more output then before, all seems to be working :)
Personally, I now use this log file for input of a daily monitoring script: check min-max available memory (= MemFree + MemCached), cpu spikes, etc. I hope it helps you out as well!
Find broken links in your cfml sourcecode
For a client which is migrating from a Windows environment to Linux, I needed to check if the source code contained broken links, due to case sensitivity on Linux. So I wrote this script, which goes through all your source files, and checks all links inside href="..." and src="..." to see if they exist.
Calling inner class of a Java Class in Railo
Thanks to the Railo documentation on Github, I finally found the answer I was searching for...
Question: how to call an inner Java class of a Java class with Railo?
Answer: use a $ sign: createObject("java", "main.java.class$innerClass")
Long version: I was busy implementing the javaEWSApi (MS Exchange Web Services API) into a new mobile project, but got stuck on getting the unread-count for the user’s Inbox. An example online showed ...
Railo Log analyzer bugfix update: v2.2.0
For anyone using the Railo log analyzer, there is an update out!
Update 2.2.0 contains:
- Added View option, to view the log file inline in the admin.
- Fixed a bug with Railo 4.0.x, which prevented the display of log files. Reason: cfdirectory filter attribute doesn't respect pipe character as delimiter anymore.
- Updated the styling, so tables and other layout looks normal again.
Check the Log analyzer page for more details, or go to the Railo extension store.
Decoding a \unicode-escaped string in CFML
Posted by Paul Klinkenberg in CFML on May 13, 2013
I needed to incorporate a news feed from yammer.com, which was pretty easy using their API. The return format is JSON, so all looked great. Except for the "rich text" they sent back:
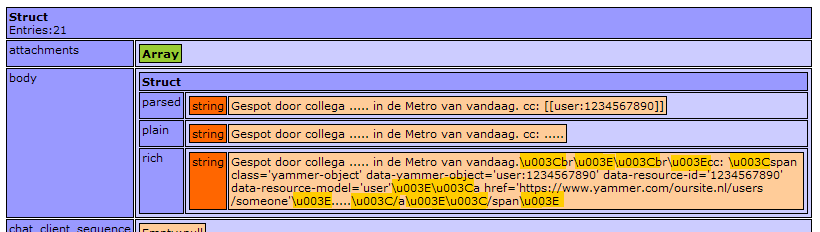
As you can see, there are a lot of "\u00.." occurences in the rich text. I searched Google for a standard CFML solution to convert these character sequences, but found nothing for CFML. So I wrote the following function, which tries to convert the string as fast as possible:
<cffunction name="unicodeEscape" returntype="string" output="no">
<cfargument name="s" type="string"/>
<!--- If no unicode-escapes present in the string: return --->
<cfif not find('\u', arguments.s)>
<cfreturn arguments.s />
</cfif>
<!--- If % is present in the string: url-encode it. Otherwise, urlDecode would choke on it --->
<cfif find('%', arguments.s)>
<cfset arguments.s = replace(arguments.s, '%', urlEncodedFormat('%'), 'all') />
</cfif>
<!--- Ascii characters (\u0000 - \u00FF) can be translated as %00-%FF --->
<cfset arguments.s = replace(arguments.s, "\u00", "%", "all") />
<!--- Higher characters (\u0100 - \uFFFF) can be translated as %01%00 - %FF%FF.
Only do this regex if there is something to replace. --->
<cfif find('\u', arguments.s)>
<cfset arguments.s = rereplace(arguments.s, "\u([0-9A-F][0-9A-F])([0-9A-F][0-9A-F])", "%\1%\2", "all") />
</cfif>
<cfreturn urldecode(arguments.s) />
</cffunction>
If there is a built-in way in CFML to decode unicode-escapes, then please leave a comment. I'd be happy to learn :)
Recent Comments